介绍
Spark History Server(Spark历史服务器)是一个用于查看和分析Spark应用程序历史记录的工具。它提供了一个web界面,用于浏览已完成的Spark应用程序的详细信息、任务执行情况、作业和阶段的统计数据等。
Spark History Server的主要功能如下:
- 查看应用程序历史记录:Spark History Server可以展示已完成的Spark应用程序的详细信息,包括应用程序的名称、提交时间、持续时间等。你可以通过界面浏览每个应用程序的概要信息。
- 浏览任务的执行情况:Spark History Server提供了一个任务列表,显示了应用程序中每个任务的执行情况,包括任务的ID、状态、启动时间、完成时间等。你可以查看每个任务的详细日志和指标,以便分析任务的性能和调优。
- 分析作业和阶段: Spark History Server还提供了作业和阶段的统计数据。你可以查看每个作业和阶段的执行时间、任务数量、输入输出大小等信息。这有助于理解应用程序的整体结构和性能瓶颈。
- 比较应用程序:Spark History Server允许你同时加载多个应用程序的历史记录,并进行比较分析。你可以选择不同的应用程序进行对比,以便了解他们之间的差异和性能变化。
通过使用Spark History Server,你可以更好地了解和分析已完成的Spark应用程序,从而优化应用程序的性能、调整资源分配和调试潜在的问题。它对于开发人员、数据工程师和运维团队来说都是一个有价值的工具。
需要注意的是,为了使用Spark History Server,你需要在Spark配置文件中启用事件日志记录,并将事件日志保存到指定的目录中。然后,你可以启动Spark History Server并指定事件日志的目录,它将加载并展示相应的历史记录。
History Server部署
由于我们使用的是Spark on k8s,所以这里介绍在k8s的部署。
创建PVC
创建对应pvc,保存Spark程序的eventLog归档数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: spark-historyserver
namespace: spark
spec:
storageClassName: nfs-152-data
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
# kubectl apply -f spark-historyserver-pvc.yaml
|
创建ConfigMap
创建对应ConfigMap,保存eventLog相关配置信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
kind: ConfigMap
apiVersion: v1
metadata:
name: spark-historyserver
namespace: spark
data:
spark-defaults.conf: |
spark.eventLog.enabled true
spark.eventLog.compress true
spark.eventLog.dir file:///opt/spark/eventLog
spark.yarn.historyServer.address localhost:18080
spark.history.ui.port 18080
spark.history.fs.logDirectory file:///opt/spark/eventLog
# kubectl apply -f configmap.yaml
|
参数解释:
- spark.eventLog.enabled:指定是否启用时间日志记录。设置为true表示启用事件日志记录,spark应用程序的事件将被记录下来。
- spark.eventLog.compress:指定是否对事件日志进行压缩。设置为true表示启用压缩,事件日志将以压缩的方式存储。
- spark.eventLog.dir:指定事件日志的存储目录。这里的配置中,事件日志将存储在/opt/spark/eventLog目录下。file://前缀表示这是一个本地文件系统路径。
- spark.yarn.historyServer.address:指定YARN的历史服务器的地址。历史服务器用于存储和展示Spark应用程序的历史信息。在这里的配置中,历史服务器的地址是localhost:18080,表示历史服务器运行在本地主机的18080端口上。
- spark.history.ui.port:指定spark历史服务器的UI界面的端口。在这里的配置中,spark历史服务器的UI界面将在18080端口上提供。
- spark.history.fs.logDirectory:指定历史日志文件的存储目录。这里的配置中,事件日志将存储在/opt/spark/eventLog目录下。file://前缀表示这是一个本地文件系统路径。
创建Deployment和Service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: spark
labels:
app: spark-historyserver
name: spark-historyserver
name: spark-historyserver
spec:
replicas: 1
selector:
matchLabels:
name: spark-historyserver
template:
metadata:
namespace: spark
labels:
app: spark-historyserver
name: spark-historyserver
spec:
containers:
- name: spark-historyserver
image: apache/spark:v3.3.2
imagePullPolicy: IfNotPresent
args: ["/opt/spark/bin/spark-class", "org.apache.spark.deploy.history.HistoryServer"]
env:
- name: TZ
value: Asia/Shanghai
- name: HADOOP_USER_NAME
value: root
- name: SPARK_USER
value: root
# 如果不使用configmap,则通过SPARK_HISTORY_OPTS配置
# - name: SPARK_HISTORY_OPTS
# value: "-Dspark.eventLog.enabled=true -Dspark.eventLog.dir=file:///opt/spark/eventLog -Dspark.history.fs.logDirectory=file:///opt/spark/eventLog"
ports:
- containerPort: 18080
volumeMounts:
- name: spark-conf
mountPath: /opt/spark/conf/spark-defaults.conf
subPath: spark-defaults.conf
- name: spark-historyserver
mountPath: /opt/spark/eventLog
volumes:
- name: spark-conf
configMap:
name: spark-historyserver
- name: spark-historyserver
persistentVolumeClaim:
claimName: spark-historyserver
---
kind: Service
apiVersion: v1
metadata:
namespace: spark
name: spark-historyserver
spec:
type: NodePort
ports:
- port: 18080
nodePort: 30601
selector:
name: spark-historyserver
# kubectl apply -f spark-historyserver.yaml
|
部署后访问
使用测试
SparkPi测试
SparkPi 是基于 Apache Spark 的一个示例应用程序,用于计算圆周率的近似值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
#在spark目录下执行
./bin/spark-submit \
--name SparkPi \
--verbose \
--master k8s://https://172.16.7.132:6443 \
--deploy-mode cluster \
--conf spark.network.timeout=300 \
--conf spark.executor.instances=3 \
--conf spark.driver.cores=1 \
--conf spark.executor.cores=1 \
--conf spark.driver.memory=1024m \
--conf spark.executor.memory=1024m \
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/pi-wc.log" \
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/pi-wc.log" \
--conf spark.eventLog.enabled=true \
--conf spark.eventLog.dir=file:///opt/spark/eventLog \
--conf spark.history.fs.logDirectory=file:///opt/spark/eventLog \
--conf spark.kubernetes.namespace=spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sa \
--conf spark.kubernetes.authenticate.executor.serviceAccountName=spark-sa \
--conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \
--conf spark.kubernetes.container.image=apache/spark:v3.3.2 \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.spark-logs-pvc.mount.path=/opt/spark/logs \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.spark-logs-pvc.options.claimName=spark-logs-pvc \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.eventlog-pvc.mount.path=/opt/spark/eventLog \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.eventlog-pvc.options.claimName=spark-historyserver \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-logs-pvc.mount.path=/opt/spark/logs \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-logs-pvc.options.claimName=spark-logs-pvc \
--conf spark.kubernetes.driverEnv.TZ=Asia/Shanghai \
--conf spark.kubernetes.executorEnv.TZ=Asia/Shanghai \
--class org.apache.spark.examples.SparkPi \
local:///opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar \
1000
|
参数解释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
./bin/spark-submit \ #命令路径
--name SparkPi \ #指定应用程序的名称
--verbose \ #指定spark-submit输出详细的日志信息
--master k8s://https://172.16.7.132:6443 \ #指定k8s集群的地址
--deploy-mode cluster \ #部署模式,这里是集群模式
--conf spark.network.timeout=300 \ #设置spark网络超时时间为300秒
--conf spark.executor.instances=3 \ #设置执行器实例数为3
--conf spark.driver.cores=1 \ #设置驱动程序使用的CPU核数为1
--conf spark.executor.cores=1 \ #设置执行器使用的CPU核数为1
--conf spark.driver.memory=1024m \ #设置驱动程序的内存为1024MB
--conf spark.executor.memory=1024m \ #设置执行器的内存为1024MB
#设置驱动程序的额外java选项。这个参数用于设置驱动程序的 Java 系统属性,其中包括 io.netty.tryReflectionSetAccessible 和 log.file。
--conf spark.driver.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/pi-wc.log" \
#设置执行器的额外 Java 选项。这个参数用于设置执行器的 Java 系统属性,其中包括 io.netty.tryReflectionSetAccessible 和 log.file。
--conf spark.executor.extraJavaOptions="-Dio.netty.tryReflectionSetAccessible=true -Dlog.file=/opt/spark/logs/pi-wc.log" \
--conf spark.eventLog.enabled=true \ #启用Spark事件日志记录。
--conf spark.eventLog.dir=file:///opt/spark/eventLog \ #设置事件日志记录的目录
--conf spark.history.fs.logDirectory=file:///opt/spark/eventLog \ #设置历史服务器的日志目录
--conf spark.kubernetes.namespace=spark \ #k8s中spark应用程序的命名空间
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark-sa \ #设置驱动程序在k8s的sa
--conf spark.kubernetes.authenticate.executor.serviceAccountName=spark-sa \ #设置执行器在k8s的sa
--conf spark.kubernetes.container.image.pullPolicy=IfNotPresent \ #设置k8s镜像的拉取策略
--conf spark.kubernetes.container.image=apache/spark:v3.3.2 \ #指定容器镜像的名称和版本
#设置驱动程序的持久化卷挂载路径,这个参数指定了将持久化卷挂载到驱动程序容器的路径。
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.spark-logs-pvc.mount.path=/opt/spark/logs \
#设置驱动程序的pvc名称。这个参数指定了要使用的pvc的名称。
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.spark-logs-pvc.options.claimName=spark-logs-pvc \
#设置驱动程序的事件日志持久化卷挂载路径。这个参数指定了将事件日志持久化卷挂载到驱动程序容器的路径。
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.eventlog-pvc.mount.path=/opt/spark/eventLog \
# 设置驱动程序的事件日志pvc名称。这个参数指定了要使用的事件日志pvc的名称。
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.eventlog-pvc.options.claimName=spark-historyserver \
#设置执行器的持久化卷挂载路径。这个参数指定了将持久化卷挂载到执行器容器的路径。
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-logs-pvc.mount.path=/opt/spark/logs \
#设置执行器的pvc名称。这个参数指定了要使用的pvc的名称。
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.spark-logs-pvc.options.claimName=spark-logs-pvc \
--conf spark.kubernetes.driverEnv.TZ=Asia/Shanghai \ #设置驱动程序容器的时区。
--conf spark.kubernetes.executorEnv.TZ=Asia/Shanghai \ #设置执行器容器的时区
--class org.apache.spark.examples.SparkPi \ #指定要运行的spark应用程序的主类
local:///opt/spark/examples/jars/spark-examples_2.12-3.3.2.jar \ #指定要运行的Spark应用程序的JAR文件路径
1000 #SparkPi示例应用程序的参数
|
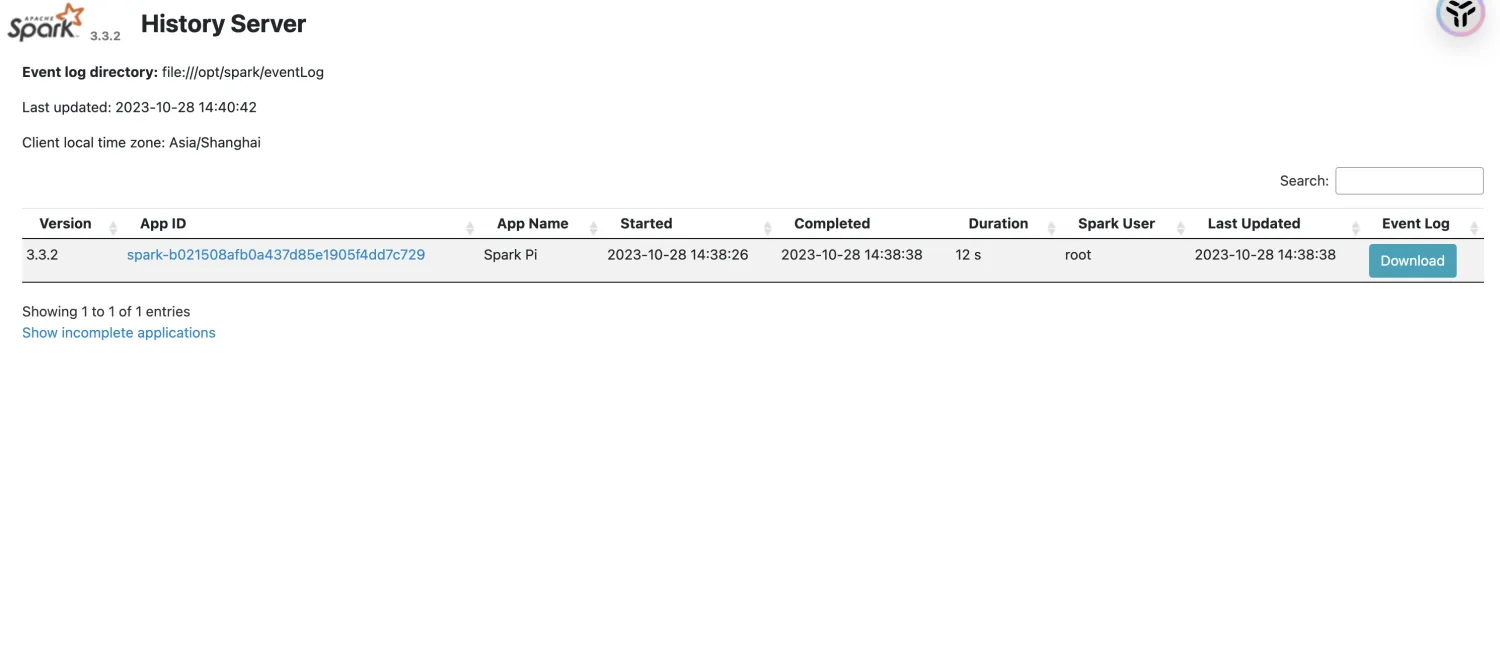
作业被记录
参考链接
https://spark.apache.org/docs/3.3.2/running-on-kubernetes.html
https://spark.apache.org/docs/3.3.2/monitoring.html
 支付宝
支付宝
 微信
微信